组件Spark
什么是Apache Spark?
答案:Apache Spark是一个快速、通用的集群计算系统,旨在处理大规模数据处理和分析任务。它提供了高级的编程模型和丰富的库,可以在分布式环境中进行数据处理、机器学习、图计算等。
Spark和Hadoop有什么区别?
答案:Spark和Hadoop都是用于大数据处理的框架,但有以下区别:
- 数据处理模型:Spark提供了更灵活和高级的数据处理模型,如RDD(弹性分布式数据集)和DataFrame,而Hadoop使用的是基于MapReduce的批处理模型。
- 性能:由于Spark的内存计算和任务调度优化,它通常比Hadoop的MapReduce更快。
- 生态系统:Hadoop拥有更成熟和广泛的生态系统,包括HDFS、YARN和Hive等,而Spark在某些方面的生态系统仍在发展中。
Spark的核心组件是什么?
答案:Spark的核心组件包括:
- Spark Core:提供了Spark的基本功能,包括任务调度、内存管理和分布式数据处理等。
- Spark SQL:用于处理结构化数据的模块,支持SQL查询和DataFrame API。
- Spark Streaming:用于实时数据流处理的模块,支持高吞吐量和低延迟的流处理任务。
- MLlib:Spark的机器学习库,提供了常见的机器学习算法和工具。
- GraphX:Spark的图计算库,用于图处理和分析任务。
Spark的数据处理模型是什么?
答案:Spark的数据处理模型基于RDD(弹性分布式数据集)。RDD是一个可并行操作的、容错的、不可变的数据集合,可以在集群中进行分布式处理。Spark还引入了DataFrame和Dataset等高级抽象,提供了更丰富和优化的数据处理能力。
Spark支持哪些编程语言?
答案:Spark主要支持以下编程语言:
- Scala:Scala是Spark的主要编程语言,它是一种面向对象和函数式编程的语言,提供了强大的表达能力和丰富的特性。
- Java:Spark可以通过Java API进行编程,适用于Java开发者。
- Python:Spark提供了Python API(PySpark),可以使用Python语言进行Spark开发。
- R:Spark也支持R语言,通过SparkR库可以在R环境中使用Spark。
Spark的调度器是什么?
答案:Spark的调度器是负责将任务分配给集群中的执行节点的组件。Spark有两种调度器:
- FIFO调度器:按照任务提交的顺序依次执行,适用于简单的任务场景。
- Fair调度器:根据资源使用情况动态分配资源,以保证每个任务能够公平地获得执行机会。
Spark的数据持久化机制是什么?
答案:Spark使用RDD的持久化机制来将数据存储在内存或磁盘中,以加快后续操作的速度。它支持将RDD的数据持久化到内存、磁盘或者序列化到外部存储系统。
Spark的容错机制是什么?
答案:Spark的容错机制基于RDD的不可变性和记录操作的转换日志。当节点发生故障时,Spark可以根据转换日志重新计算丢失的数据,从而保证任务的容错性。
Spark的机器学习库是什么?
答案:Spark的机器学习库称为MLlib,它提供了常见的机器学习算法和工具,如分类、回归、聚类、推荐等。MLlib使用RDD和DataFrame作为数据接口,提供了易于使用和可扩展的机器学习功能。
Spark的图计算库是什么?
答案:Spark的图计算库称为GraphX,它提供了图处理和分析的功能,包括图的创建、遍历、连接等操作。GraphX使用RDD作为图数据的表示形式,并提供了丰富的图算法和操作符。
Spark支持哪些数据源和数据格式?
答案:Spark支持多种数据源和数据格式,包括:
- 文件系统:Spark可以读写各种文件系统,如HDFS、本地文件系统、S3等。
- 数据库:Spark可以连接和读写关系型数据库,如MySQL、PostgreSQL等,也支持NoSQL数据库,如MongoDB、Cassandra等。
- 实时数据流:Spark支持读取实时数据流,如Kafka、Flume等。
- 数据格式:Spark支持常见的数据格式,如CSV、JSON、Parquet、Avro等。
Spark的集群部署模式有哪些?
答案:Spark的集群部署模式包括:
- Standalone模式:在独立的Spark集群上运行,不依赖其他资源管理器。
- YARN模式:在Hadoop集群上利用YARN资源管理器进行任务调度和资源分配。
- Mesos模式:在Mesos集群上利用Mesos资源管理器进行任务调度和资源分配。
- Kubernetes模式:在Kubernetes集群上运行Spark作业,利用Kubernetes进行容器管理和资源分配。
Spark的优化技术有哪些?
答案:Spark的优化技术包括:
- 延迟计算:Spark使用惰性求值策略,延迟计算数据,只在需要结果时才执行计算,减少不必要的中间结果。
- 数据分区和并行度:合理设置数据分区和并行度,使得任务可以并行执行,提高计算效率。
- 内存管理:通过合理配置内存和缓存策略,将常用的数据存储在内存中,减少磁盘IO,提高性能。
- 窗口操作:对于窗口操作,使用时间滑动窗口和窗口聚合等技术,减少数据的重复计算。
- 数据压缩和序列化:使用压缩和序列化技术减小数据的存储空间和传输成本。
Spark支持哪些集群调度器?
答案:Spark支持以下集群调度器:
- Hadoop YARN:Spark可以与Hadoop集群上的YARN资源管理器集成,利用YARN进行任务调度和资源分配。
- Apache Mesos:Spark可以与Mesos集群集成,利用Mesos进行任务调度和资源分配。
- Kubernetes:Spark可以在Kubernetes集群上运行,利用Kubernetes进行容器管理和资源分配。
Spark的数据处理模型中的RDD是什么?
答案:RDD(弹性分布式数据集)是Spark的核心数据结构,代表分布在集群中的不可变的、可分区的数据集合。RDD可以并行操作,支持容错和恢复。它是Spark进行分布式数据处理的基础。
Spark的DataFrame是什么?
答案:DataFrame是Spark提供的高级数据结构,用于处理结构化数据。DataFrame类似于传统数据库中的表格,具有列和行的概念,支持SQL查询和DataFrame API操作。DataFrame提供了更丰富的数据处理能力和优化技术,比原始的RDD更高效。
Spark的机器学习库MLlib有哪些常见的算法?
答案:Spark的机器学习库MLlib包含了多种常见的机器学习算法,包括分类算法(如逻辑回归、决策树、随机森林)、回归算法(如线性回归、岭回归)、聚类算法(如K均值聚类、高斯混合模型)、推荐算法(如协同过滤)、降维算法(如主成分分析)、自然语言处理(如文本分类、词嵌入)等。
Spark的图计算库GraphX支持哪些图算法?
答案:Spark的图计算库GraphX支持多种图算法,包括图的遍历、连接、聚合、PageRank、连通性组件、最短路径等。GraphX提供了丰富的图操作符和API,方便用户进行图处理和分析。
Spark Streaming是什么?
答案:Spark Streaming是Spark提供的实时数据流处理模块。它可以以微批处理的方式处理实时数据,支持高吞吐量和低延迟的数据处理。Spark Streaming可以与Spark的批处理和机器学习库无缝集成,实现批处理与实时处理的统一。
Spark的扩展库和整合工具有哪些?
答案:Spark有丰富的扩展库和整合工具,包括:
- Spark SQL:用于处理结构化数据,支持SQL查询和DataFrame操作。
- Spark Streaming:用于实时数据流处理。
- MLlib:Spark的机器学习库。
- GraphX:Spark的图计算库。
- SparkR:提供在R语言中使用Spark的能力。
- PySpark:Spark的Python API。
- Spark on Kubernetes:在Kubernetes集群上运行Spark作业。
- Spark on Mesos:在Mesos集群上运行Spark作业。
- Spark on YARN:在Hadoop YARN集群上运行Spark作业。
什么是宽依赖,什么是窄依赖?哪些算子是宽依赖,哪些是窄依赖?
窄依赖就是一个父RDD分区对应一个子RDD分区,如map,filter
或者多个父RDD分区对应一个子RDD分区,如co-partioned join
宽依赖是一个父RDD分区对应非全部的子RDD分区,如groupByKey,ruduceByKey
或者一个父RDD分区对应全部的子RDD分区,如未经协同划分的join
Transformation和action算子有什么区别?举例说明
Transformation 变换/转换:这种变换并不触发提交作业,完成作业中间过程处理。Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算
map, filter
Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。
Action 算子会触发 Spark 提交作业(Job)。
count
讲解spark shuffle原理和特性?shuffle write 和 shuffle read过程做些什么?
Shuffle数据块有多少种不同的存储方式?分别是什么
- RDD数据块:用来存储所缓存的RDD数据。
- Shuffle数据块:用来存储持久化的Shuffle数据。
- 广播变量数据块:用来存储所存储的广播变量数据。
- 任务返回结果数据块:用来存储在存储管理模块内部的任务返回结果。通常情况下任务返回结果随任务一起通过Akka返回到Driver端。但是当任务返回结果很大时,会引起Akka帧溢出,这时的另一种方案是将返回结果以块的形式放入存储管理模块,然后在Driver端获取该数据块即可,因为存储管理模块内部数据块的传输是通过Socket连接的,因此就不会出现Akka帧溢出了。
- 流式数据块:只用在Spark Streaming中,用来存储所接收到的流式数据块
哪些spark算子会有shuffle?
- 去重,distinct
- 排序,groupByKey,reduceByKey等
- 重分区,repartition,coalesce
- 集合或者表操作,interection,join
讲解spark schedule(任务调度)?
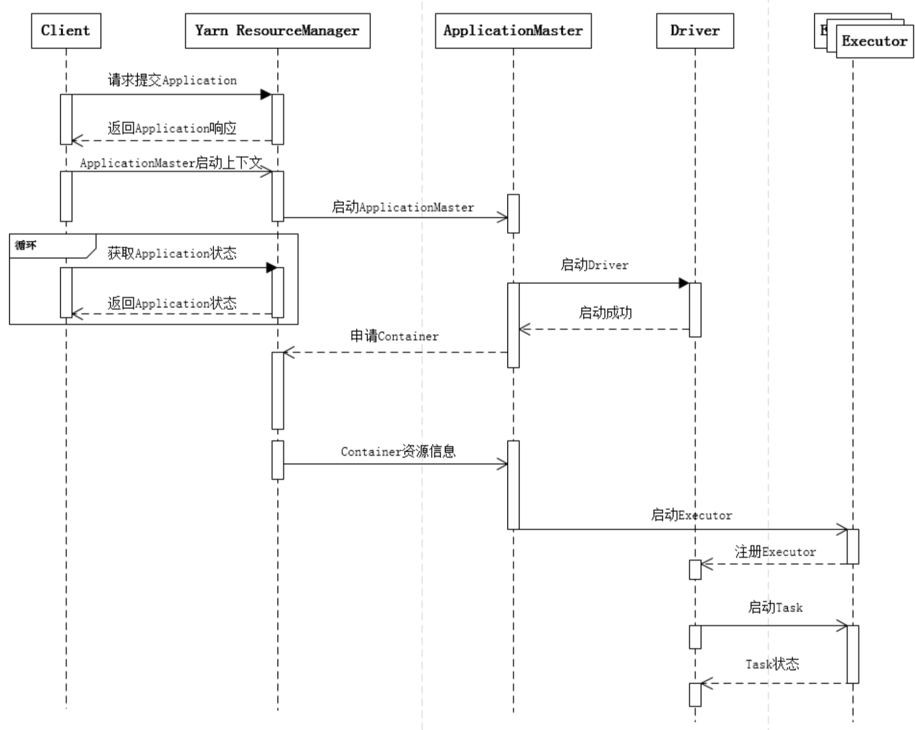
Spark stage是如何划分的?
- 从hdfs中读取文件后,创建 RDD 对象
- DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG
- 每一个JOB被分为多个Stage,划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。
Spark cache一定能提升计算性能么?说明原因?
不一定啊,cache是将数据缓存到内存里,当小数据量的时候是能提升效率,但数据大的时候内存放不下就会报溢出。
Cache和persist有什么区别和联系?
cache调用了persist方法,cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。
RDD是弹性数据集,“弹性”体现在哪里呢?你觉得RDD有哪些缺陷?
- 自动进行内存和磁盘切换
- 基于lineage的高效容错
- task如果失败会特定次数的重试
- stage如果失败会自动进行特定次数的重试,而且只会只计算失败的分片
- checkpoint【每次对RDD操作都会产生新的RDD,如果链条比较长,计算比较笨重,就把数据放在硬盘中】和persist 【内存或磁盘中对数据进行复用】(检查点、持久化)
- 数据调度弹性:DAG TASK 和资源管理无关
- 数据分片的高度弹性repartion
缺陷:
惰性计算的缺陷也是明显的:中间数据默认不会保存,每次动作操作都会对数据重复计算,某些计算量比较大的操作可能会影响到系统的运算效率
RDD有多少种持久化方式?memory_only如果内存存储不了,会怎么操作?
cache和persist
- memory_and_disk,放一部分到磁盘
- MEMORY_ONLY_SER:同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销。
- MEMORY_AND_DSK_SER:同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象。
- DISK_ONLY:使用非序列化Java对象的方式持久化,完全存储到磁盘上。
MEMORY_ONLY_2或者MEMORY_AND_DISK_2等:如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可。
RDD分区和数据块有啥联系?
当GC时间占比很大可能的原因有哪些?对应的优化方法是?
垃圾回收的开销和对象合数成正比,所以减少对象的个数,就能大大减少垃圾回收的开销。序列化存储数据,每个RDD就是一个对象。缓存RDD占用的内存可能跟工作所需的内存打架,需要控制好
Spark中repartition和coalesce异同?coalesce什么时候效果更高,为什么?
repartition(numPartitions:Int):RDD[T]
coalesce(numPartitions:Int, shuffle:Boolean=false):RDD[T]以上为他们的定义,区别就是repartition一定会触发shuffle,而coalesce默认是不触发shuffle的。
他们两个都是RDD的分区进行重新划分,repartition只是coalesce接口中shuffle为true的简易实现,(假设RDD有N个分区,需要重新划分成M个分区)
减少分区提高效率
Groupbykey和reducebykey哪个性能更高,为什么?
reduceByKey性能高,更适合大数据集
你是如何理解caseclass的?
Scala里trait有什么功能,与class有何异同?什么时候用trait什么时候该用class?
它可以被继承,而且支持多重继承,其实它更像我们熟悉的接口(interface),但它与接口又有不同之处是:
trait中可以写方法的实现,interface不可以(java8开始支持接口中允许写方法实现代码了),这样看起来trait又很像抽象类
Scala 语法中to 和 until有啥区别?
to 包含上界,until不包含上界
讲解Scala伴生对象和伴生类?
单例对象与类同名时,这个单例对象被称为这个类的伴生对象,而这个类被称为这个单例对象的伴生类。伴生类和伴生对象要在同一个源文件中定义,伴生对象和伴生类可以互相访问其私有成员。不与伴生类同名的单例对象称为孤立对象。
import scala.collection.mutable.Map
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte) {
sum += b
}
def checksum(): Int = ~(sum & 0xFF) + 1
}
object ChecksumAccumulator {
private val cache = Map[String, Int]()
def calculate(s: String): Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
println("s:"+s+" cs:"+cs)
cs
}
def main(args: Array[String]) {
println("Java 1:"+calculate("Java"))
println("Java 2:"+calculate("Java"))
println("Scala :"+calculate("Scala"))
}
}spark作业执行流程?
- 客户端提交作业
- Driver启动流程
- Driver申请资源并启动其余Executor(即Container)
- Executor启动流程
- 作业调度,生成stages与tasks。
- Task调度到Executor上,Executor启动线程执行Task逻辑
- Driver管理Task状态
- Task完成,Stage完成,作业完成